Christian Kaul and Lars Rönnbäck
It’s incredible how many years I wasted associating complexity and ambiguity with intelligence. Turns out the right answer is usually pretty simple, and complexity and ambiguity are how terrible people live with themselves.
David Klion (2018)
Many organizations today struggle with a strong disconnect between their understanding of the work they are doing and the way their IT systems are set up.
Data is distributed over a large number of nonintegrated IT systems and manual interfaces (sometimes called “human middleware”) exist between incompatible applications. Within these applications, data may also be subject to regulations, and compliance is difficult to achieve. We can trace most, if not all, of these issues back to an abundance of unspecific, inflexible, and non-aligned data models underlying the applications these organizations use to conduct their business.
In this article, the first in a series, we briefly describe the issues resulting from this disconnect and their origins within a traditional organization. We then suggest a radical shift, to a model-driven organization, where all applications work towards a single data platform with a unified model. Instead of creating models that mirror the existing organization and its dysfunctions, we suggest first creating a unified model based on the goals of the organization, and thereafter derive the organizational structure and the necessary applications from it.
Technologically, databases are now appearing in the market that can manage OLTP (operational) and OLAP (analytical) loads simultaneously, with associated app stores and application development frameworks, thereby enabling organizations to become model-driven.
Motivation
All organizations create data. When you’re using computers (and who isn’t these days), everything you do produces data. Therefore it’s not surprising that data is becoming an ever more important asset to manage.
Pretty much all organizations therefore store data in various shapes and forms. Putting this data to good use is the natural next step on the agenda and organizations that are successful in that respect claim to be data-driven.
The transition from giving little attention to data to becoming data-driven has been gradual, and many businesses have yet to organize themselves around data. Rather, data is predominantly organized around business processes. Unification of the available data is done far downstream, after it has passed through the organizational structure, the people in the different departments, the applications they use, and the databases in which they have stored it.
These databases also have their own application-specific models, creating a disparate data structure landscape that is hard to navigate, and unification of these is usually a resource-intensive and ongoing task in an organization. This leads to confusion, frustration and an often abysmal return on investment for data initiatives.
Processes
Ultimately, organizations have some set of goals they wish to fulfill. These can be goals for the organization itself (profit, market share, etc), but also goals related to their customers (satisfaction, loyalty, etc), their employees (health, efficiency, etc), applicable regulations (GDPR, SOX, etc.), or society as a whole (sustainability, equality, etc.).
The organization then structures itself in some way based on a perception on how to best work on reaching these goals. This perception is often influenced by current management trends, with flavors like functional, matrix, project, composite, and team-based organizational structures. There are also various frameworks associated with these describing ways of working within the organization, such as ITIL, SAFe, Lean, DevOps, and Six Sigma.
The sheer number of flavors and frameworks gaining and falling in popularity should be a warning sign that something is amiss. We believe that all of these treat the symptoms, but neither get at the root cause of the problem.
Technology
A heterogenous application and data store landscape within an organization is a strong detractor from achieving a unified view of the data they contain.
There are a plethora of job titles related to dealing with this heterogeneity: enterprise architect, integration architect, data warehouse architect, and the like. There are also different more or less systematic approaches, such as enterprise messaging systems, microservices, master data management, modern data stack, data mesh, data fabric, data lake, data warehouse, data lakehouse, and so on.
Again, the sheer number of titles and approaches and their gaining and falling in popularity should be a warning sign that something is amiss. We believe that also all of these treat the symptoms, but neither get at the root cause of the problem.
Problem Statement
The problem is that the way an organization is intended to work is usually misaligned with how it actually works, due to a number of factors distancing the ideal way of working from the de-facto way of working.
Some of these factors causing misalignment are:
- The goals of the organization are vague and fuzzy and localized to some select individuals.
- The de-facto way of working is a heritage from a different time.
- The de-facto way of working strays from the ideal because of management fads.
- The de-facto way of working is externally incentivized by vendors who benefit from it.
- The de-facto way of working is a compromise due to technological limitations.
- The de-facto way of working is sufficient to be profitable.
In future articles, we will show how these misalignment factors can be addressed in a model-driven organization, bringing its way of working much closer to the ideal.
We also believe that the significant divide between created data and actionable data found in most organizations is debilitating, since actionable data is what in the end creates value for the organization.
Data and Organizations
While products or services tend to leave the organization, data usually does not. It is the remainder of the daily operations, the breadcrumbs of human activity inside the organization, and as such the source from which an organization may learn, adapt and evolve.
If the collective knowledge of an organization only resides in the memories of its employees, it will never be utilized to its full potential. Even worse, given high record-high turnover (what some call “the great resignation”), this knowledge is leaving the organization at a dangerously high rate. This is especially harmful because it’s usually not the least competent, least experienced people leaving, quite the opposite.
Harnessing the full potential of the knowledge hidden in its data is therefore a necessity in the “survival of the fittest”-style environment most organizations face today. The survival of the organization depends on it, not figuratively but literally. Therefore, the data an organization creates must be stored, and stored in a way that makes it readily actionable.
The Traditional Approach
Looking at the architecture of a traditional organization (Figure 1), the organizational structure is formed to satisfy its goals.
The people working within this organizational structure buy and sometimes build applications that simplify their daily operations or solve specific problems. These applications create data, often stored in some database local to each application.
Data is then integrated from the disparate models found in the many application databases into a single database with a unified model. Analytics based on this unifiedly modeled data help people understand the ongoings in the organization and indicators show whether or not it is on the right track to achieving its goals.
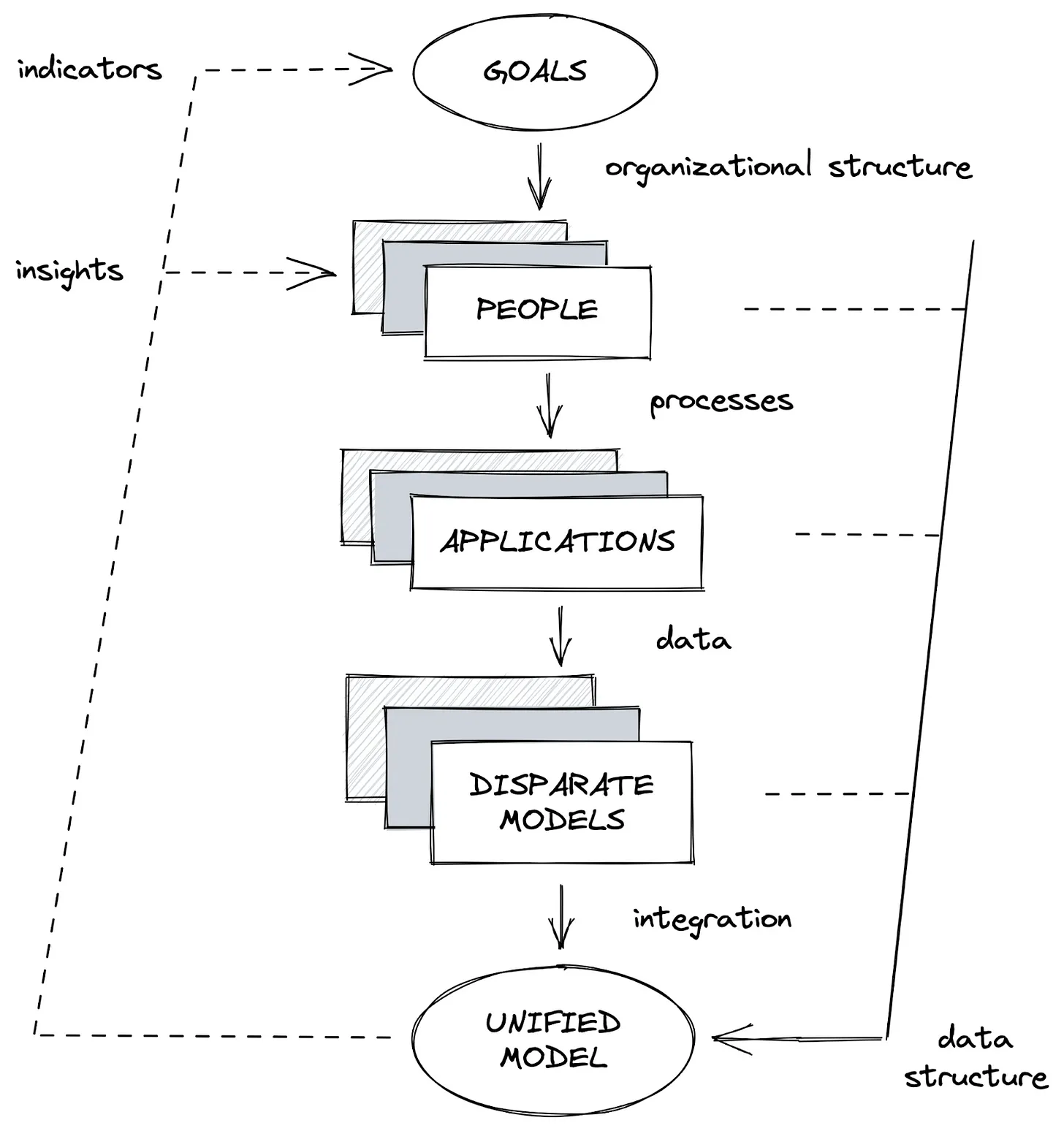
In this architecture, there is a divide between created data and actionable data. This divide also reduces the capacity with which the organization can assess its progress towards its goals.
Trying to Make Sense of Your Data
Data is created far from where it is analyzed, and data creation is often governed by third-party applications made for organizations in general, not custom-made for a specific organization.
The models those applications have chosen for the data they create rarely align perfectly with the model of a particular business. In order to align data created by different applications into a unified model of the organization, data must be interpreted, transported, and integrated (the dreaded ELT processes of extracting, loading and transforming data).
Application developers usually face fewer requirements than those a unified model should serve. As an example, there is often little to no support for retaining a history of changes in the application and they show only the current state things are in. Any natural progression or corrections that may have happened just overwrite the existing data. Living up to regulations in which both of these types of changes must be kept historically can significantly raise the complexity of the architecture needed to interpret, transport, and integrate data.
Another aspect that is complicating the architecture is the need for doing near real-time analytics. Interpreting, transporting, and integrating data are time-consuming operations, so achieving zero latency is impossible, not even with a massive increase in the ETL process execution frequency.
Data in the unified model is therefore never immediately actionable. Reducing this lag puts a strain on both the applications and the database serving the unified model, introduces additional challenges when it comes to surveillance and maintenance, and potentially significant cloud compute costs.
Trying to Make Sense of Someone Else’s Model
Applications that are not built in-house are normally built in a way that they are suitable for a large number of organizations. Their database models may therefore be quite extensive, in order to be able to serve many different use cases. These models also evolve with new versions of the applications.
Because of this, it is unusual that all possible data is interpreted, transported, and integrated into the unified model. Instead some subset is selected. Because of new requirements or applications evolving, this subset often has to be revised. Adapting to such changes can consume significant portions of the available time for maintenance of the unified model.
Maintaining a separate database with a unified model also comes with a monetary cost. Staff is needed with specialist skills in building unified models and logic for interpreting, transporting, and integrating data, while also maintaining these over time. On top of that is the cost of keeping a separate database to hold the unified model. Depending on whether this is in the cloud or on premise, there may be different costs associated with licensing, storage, compute, and backups.
Fragmentation
In larger or more complex organizations, the specialists can rarely comprehend and be responsible for all sources, given the number of applications used.
This results in hyper-specialization on some specific sources and tasks, which impairs their ability to understand and deliver on requirements that encompass areas outside of their expertise. Hyper-specialization also increases the risks of having single points of failure within the organization.
Making data actionable in the heterogenous application landscape resulting from the traditional approach outlined above requires a lot of work and carries a significant cost for the organization. There should be a better way and we’re convinced there is one. We’ll go into more detail in the next article in this series.
One thought on “Towards a Model-Driven Organization (Part 1)”