
In our paper Temporal Dimension Modeling we introduced the concept of a twine. A twine is an efficient set based algorithm that can be applied when you have a table in which you have recorded a history of changes and some other table with related points in time, for which you want to know which historical rows were in effect at those different time points.
Let us look at an example. In one table we have stored the weekly billboard rankings of songs, and in another we have information about the artists performing the songs, and a third table with song information. The billboard table references both together with a ranking and a date indicating since when that ranking came into effect.

The ranking is historized weekly, so that if the ranking has changed since last week, a new row with the new rank is added with a later ValidSince date. The table below lists rows for the song “Let’s Twist Again” by Chubby Checker.
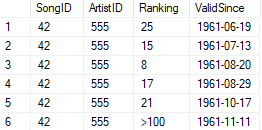
Given that we know the song was released on the 19th of June 1961, we see that it went straight into the 25th spot. It reached the 8th spot as it highest rating, and the latest information we have is that it is currently outside of the top 100. Note that for some weeks there are no rows since the ranking remained the same. This is a typical example of managing change without the introduction of data duplication. Thanks to the fact that Ranking is exhaustive, such that that it can always express a valid value, there is no need for a ValidTo column (also known as end-dating). The benefit of avoiding ValidTo is that historization can be done using a insert-only database, avoiding costly update operations.
Now, let’s assume that these tables have lots and lots of data, and we would like to know what ranking each song had one month after its release. This forces us to do a temporally dependent join, or in other words a join in which the join condition involves temporal logic. Picking up the song “Let’s Twist Again” from the Song table gives us the 1961-06-19 ReleaseDate and the SongID 42. Looking at the table above we need to find which ranking was in effect for SongID 42 on 1961-07-19 (one month later). Visually, it is easy to deduce that it was ranked 15th, since that ranking is valid since 1961-07-13 until replaced by the best ranking on 1961-08-20, and 1969-07-19 falls in between those dates.
Unfortunately relational databases are inherently bad at optimizing in between conditions. The best trick before the twine was to use a CROSS APPLY together with a TOP 1, which would give the query optimizer the additional information that only a single version can be in effect at a given point in time. Using this approach still had us, after four hours of execution time, cancelling a similar query we ran for the tests in our paper. Rewriting the query in numerous different ways using known tricks with subselects, row numbering, last value functions, and the likes, produced the same results. It was back to the drawing board.
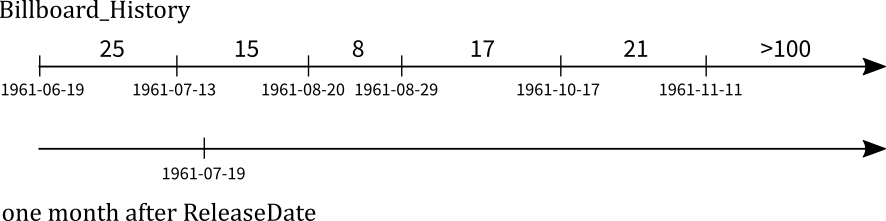
After a while we had a sketch similar to the one above on a whiteboard. I recalled having written about a very similar situation, where I called for parallel projections in databases. So, what if we could project one timeline onto another and just keep the segment where they match? We started by forming a conjoined timeline, where time points were labelled so we could determine from which timeline they had originated.
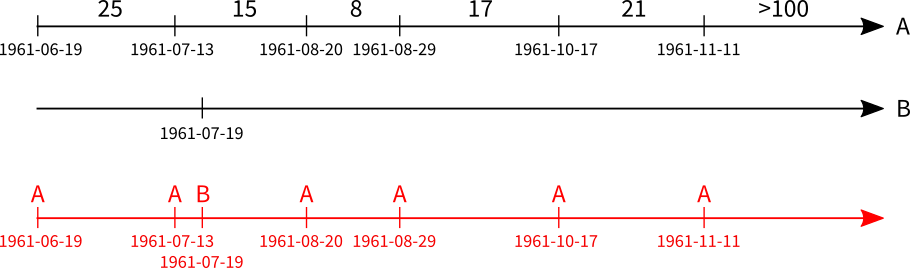
Now we just needed to traverse the conjoined timeline and at every B-point pick up the latest value of the A-point. As it turns out, conjoining can be done using a simple union operation, and finding the latest A-point value can be done using a cumulative conditional max operation. Both performance efficient operations that, at least theoretically, only requires one pass over the underlying tables, avoiding Row-By-Agonizing-Row issues.
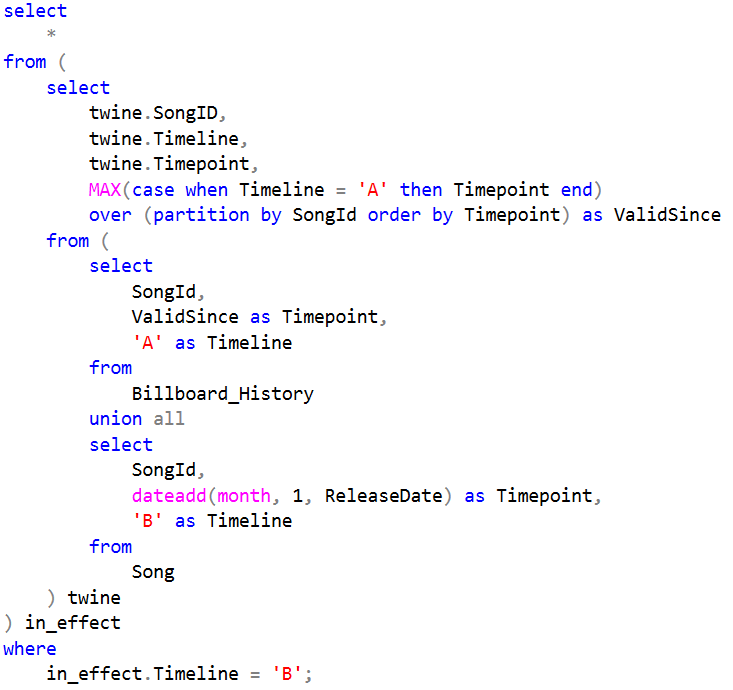
The resulting code can be seen to above. The union will combine the timelines, on which a conditional max operation is performed with a window. The condition limits the values to only A-points and the window makes sure it is picking up the the largest one for each song. Now this also gives us rows for the A (billboard history) timeline in which the Timepoint and ValidSince always will be the same. An outer condition discards these by limiting the result to those relevant for the B (songs) timeline. When looking at the actual execution plan of the query, we can see that the tables have indeed only been scanned once.

Twining is very performance efficient! To drive the point home, the mentioned query that was cancelled after four hours only took seconds to run when it was rewritten as a twine. If you are worried about the sort in the execution plan, adding some indexes (that basically precalculate the sorts) changes it into a merge join. The tradeoff is that sorting is done at write time or rather than at read time, so it will depend on your particular requirements what you choose.


Finally, as an exercise, try to produce the twine for the question: “How many artists had a top 10 hit on their 40th birthday?” Happy Twining!