Over the last decade schemaless databases have become a thing. The argument being that too much work is required at write time conforming information to the schema. Guess what, you only moved that work higher up the information refinery. In order to digest the information, it will at some point have to conform to some schema anyway, but now you have to do the work at read time instead. Would you rather spend additional time once, when writing, or spend additional time every time you read? You may also have heard me say that ‘unstructured data is just data waiting to be structured’.
That being said, there is a huge problem with schemas, but the problem is that information needs to be stored according to one rigid schema, rather than alongside many flexible schemas. The rigidity of current schema based databases often leave us no option but to peel and mold information before it fits. Obviously, discarding and deforming information is bad, so I do understand the appeal of schemaless databases, even if they fail to address the underlying issue.

The only way to store the bananas above in my stomach are to peel them and mold them through my mouth, acting much like a relational database with a particular schema. The relational database forces me to do a few good things though, things not always done in schemaless databases. Identification has to be performed, where bananas are given identities, so that we know if this is a new banana or one that is already in the stomach. Thanks to things having identities, we can also relate them to each other, such that all these bananas at one point came from the same bunch above.
Another advantage of identities, along with the ability to relate these to the identities of other things and their properties, is that we can start to talk about the things themselves. Through such metaspeak it is possible to say that a thing is of the Banana type. With this realization, it is hard to understand why a schema should be so rigidly enforced, unless metaspeak is assumed to be autocratically written in stone, while at the same time being univocal, all-encompassing, and future proof. How true does that not ring to someone living in the real world?
No, let there be diversity. Let us take the good things from relational databases, such as identification and the possibility to express relationships as well as properties, but let us not enforce a schema, taking the best part of the schemaless databases as well. Instead, let there be metaspeak expressed using the same constructs as ordinary speak, and let this metaspeak be spoken in as many ways as there are opinions. Let us talk about #schemafull databases instead!
A #schemafull database is one in which information is stored as pieces of information, posits, each tied to a an identified thing, and opinions about these pieces, assertions, made by some identified thing. What class of things a particular thing belongs to is just another piece of information, about which you may be certain to a degree, hold a different opinion than someone else, or later change your mind about. These pluralistic “schemas” live and indefinitely evolve alongside the information. There is neither no limit to how much additional description these classes and schemas can be given. They could, for example, be parts of different (virtual) layers, such as logical or conceptual, or they could be related hierarchically, such that a Banana is a Fruit.
Surely though, if we are to talk about a things and have a fruitful conversation, must we not agree upon something first? We do, of course, and what we believe to be the least to be agreed upon are necessarily identities and roles, and presumptively values. As an example, looking at the posit “This banana has the color yellow”, everyone who asserts this must agree that ‘this banana’ refers to the same thing, or in other words uniquely identifies a particular thing. The role of ‘that having a color’ must have the same meaning for everyone, in how it applies and how it is measured. Finally, ‘yellow’ should be as equally understood as possible.
The reason the value part is less constrained is simply because not all values have a rigorous definition. The color yellow is a good example. I cannot be sure that your yellow is my yellow, unless we define yellow using a range of wavelengths. However, almost none of us run around with spectrometers in our pockets. The de facto usage of yellow is different, even if we can produce and measure it scientifically. We will therefore presume that for two different assertions of the same posit “This banana has the color yellow”, both making those assertions share an understanding of ‘yellow’. There is also the possibility of representing imprecision using fuzzy values, such as ‘yellowish’, where ‘brownish’ may to some extent overlap it.
It is even possible to define an imprecise Fruitish class, which in the case of the Banana may be a good thing, since bananas botanically are berries. It’s also important to notice the difference between imprecision and uncertainty. Imprecision deals with fuzzy posits, whereas uncertainty deals with fuzzy assertions. It is possible to state that “I am certain that Bananas belong to the Fruitish class”, complete certainty about an imprecise value. Other examples are “I am not so sure that Bananas belong to the Fruit class”, uncertainty about a precise value, and “I am certain that Bananas do not belong to the Fruit class”, complete certainty about the negation of precise value.
A database needs to be able to manage all of this, and we are on our way to building one in which all this will be possible, but we are not there yet. The theory is in place, but the coding has just started. If you know or can learn to program in Rust and want to help out, contact me. You can also read more about #transitional modeling in our scientific paper, and in the articles “Schema by Design“, “The Illusion of a Fact“, “Modeling Consensus and Disagreement“, and “The Slayers of Layers“. Don’t miss Christian Kaul’s “Modeling the Transitional Data Warehouse” either, in which conflicting schemas are exemplified.
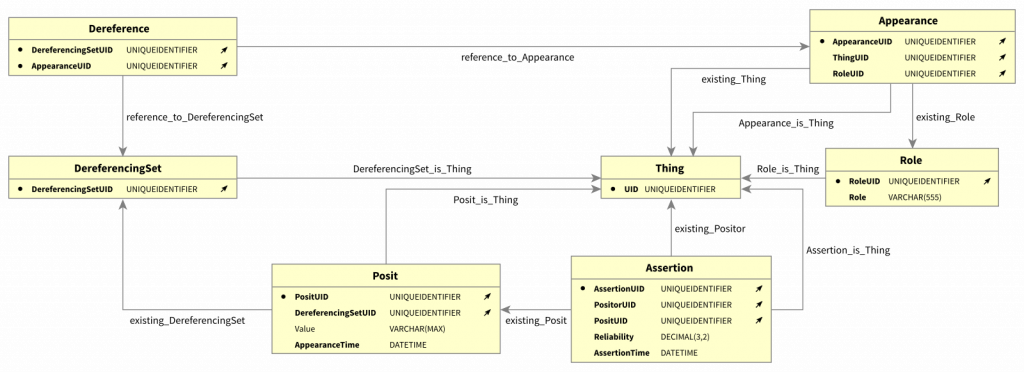
There is also an implementation of #transitional modeling in a relational database, of course only intended for educational purposes. The rigid schema of which can be seen below…
Stop peeling and molding information and start recording opinions of it instead. Embrace the schemas. Embrace #transitional modeling. Have a banana!